The central dogma of molecular genetics is cry. The Central Dogma of Molecular Genetics
The cell as such has a huge number of diverse functions, as we have already said, some of them are general cellular, some are special, characteristic of special cell types. The main working mechanisms for performing these functions are proteins or their complexes with other biological macromolecules, such as nucleic acids, lipids and polysaccharides. Thus, it is known that the processes of transport in the cell of various substances, from ions to macromolecules, are determined by the work of special proteins or lipoprotein complexes in the plasma and other cellular membranes. Almost all processes of synthesis, breakdown, and rearrangement of various proteins, nucleic acids, lipids, and carbohydrates occur as a result of the activity of protein-enzymes specific for each individual reaction. Syntheses of individual biological monomers, nucleotides, amino acids, fatty acids, sugars, etc. are also carried out by a huge number of specific enzymes - proteins. Contraction, leading to cell motility or the movement of substances and structures within cells, is also carried out by special contractile proteins. Many cell reactions in response to external factors (viruses, hormones, foreign proteins, etc.) begin with the interaction of these factors with special cellular receptor proteins.
Proteins are the main components of almost all cellular structures. The many chemical reactions within a cell are determined by many enzymes, each of which carries out one or more separate reactions. The structure of each individual protein is strictly specific, which is expressed in the specificity of their primary structure - in the sequence of amino acids along the polypeptide protein chain. Moreover, the specificity of this amino acid sequence is unmistakably repeated in all molecules of a given cellular protein.
Such correctness in reproducing an unambiguous sequence of amino acids in a protein chain is determined by the DNA structure of the gene region that is ultimately responsible for the structure and synthesis of a given protein. These ideas serve as the main postulate of molecular biology, its “dogma”. Information about the future protein molecule is transmitted to the sites of its synthesis (ribosomes) by an intermediary - messenger RNA (mRNA), the nucleotide composition of which reflects the composition and sequence of nucleotides of the gene region of DNA. A polypeptide chain is built in the ribosome, the sequence of amino acids in which is determined by the sequence of nucleotides in mRNA, the sequence of their triplets. Thus, the central dogma of molecular biology emphasizes the unidirectionality of information transfer: only from DNA to protein, with the help of an intermediate, mRNA (DNA ® mRNA ® protein). For some RNA-containing viruses, the information transmission chain can follow the RNA – mRNA – protein scheme. This does not change the essence of the matter, since the determining, determining link here is also the nucleic acid. The reverse pathways of determination from protein to nucleic acid to DNA or RNA are unknown.
In order to further move on to the study of cell structures associated with all stages of protein synthesis, we need to briefly dwell on the main processes and components that determine this phenomenon.
Currently, based on modern ideas about protein biosynthesis, the following general principle diagram of this complex and multi-stage process can be given (Fig. 16).
The main, “command” role in determining the specific structure of proteins belongs to deoxyribonucleic acid – DNA. The DNA molecule is an extremely long linear structure consisting of two intertwined polymer chains. The constituent elements - monomers - of these chains are four types of deoxyribonucleotides, the alternation or sequence of which along the chain is unique and specific for each DNA molecule and each of its sections. Different fairly long sections of the DNA molecule are responsible for the synthesis of different proteins. Thus, one DNA molecule can determine the synthesis of a large number of functionally and chemically different cell proteins. Only a certain section of the DNA molecule is responsible for the synthesis of each type of protein. Such a section of the DNA molecule associated with the synthesis of one particular protein in the cell is often referred to as a “cistron”. Currently, the concept of cistrons is considered to be equivalent to the concept of gene. The unique structure of a gene—the specific sequential arrangement of its nucleotides along the chain—contains all the information about the structure of one corresponding protein.
From the general diagram of protein synthesis it is clear (see Fig. 16) that the starting point from which the flow of information for the biosynthesis of proteins in the cell begins is DNA. Consequently, it is DNA that contains the primary record of information that must be preserved and reproduced from cell to cell, from generation to generation.
Briefly touching on the issue of where genetic information is stored, i.e. The following can be said about the localization of DNA in a cell. It has long been known that, unlike all other components of the protein synthesizing apparatus, DNA has a special, very limited localization: its location in the cells of higher (eukaryotic) organisms will be the cell nucleus. In lower (prokaryotic) organisms that do not have a formed cell nucleus, DNA is also mixed from the rest of the protoplasm in the form of one or several compact nucleotide formations. In full accordance with this, the nucleus of eukaryotes or the nucleoid of prokaryotes has long been considered as a receptacle for genes, as a unique cellular organelle that controls the implementation of the hereditary characteristics of organisms and their transmission over generations.
The basic principle underlying the macromolecular structure of DNA is the so-called complementarity principle (Fig. 17). As already mentioned, the DNA molecule consists of two intertwisted strands. These chains are linked to each other through the interaction of their opposing nucleotides. Moreover, for structural reasons, the existence of such a double-stranded structure is possible only if the opposite nucleotides of both chains are sterically complementary, i.e. will complement each other with their spatial structure. Such complementary - nucleotide pairs are the A-T pair (adenine-thymine) and the G-C pair (guanine-cytosine).
Consequently, according to this principle of complementarity, if in one chain of a DNA molecule we have a certain sequence of four types of nucleotides, then in the second chain the sequence of nucleotides will be uniquely determined, so that each A of the first chain will correspond to a T in the second chain, each T of the first chain will correspond to an A in the second chain, to each G of the first chain - C in the second chain and to each C of the first chain - G in the second chain.
It can be seen that the indicated structural principle underlying the double-stranded structure of the DNA molecule makes it easy to understand the exact reproduction of the original structure, i.e. accurate reproduction of information recorded in the chains of a molecule in the form of a specific sequence of 4 types of nucleotides. Indeed, the synthesis of new DNA molecules in a cell occurs only on the basis of existing DNA molecules. In this case, the two chains of the original DNA molecule begin to diverge at one end, and at each of the diverged single-stranded sections, the second chain begins to assemble from the free nucleotides present in the environment in strict accordance with the principle of complementarity. The process of divergence of the two chains of the original DNA molecule continues, and accordingly both chains are complemented by complementary chains. As a result, as can be seen in the diagram, instead of one, two DNA molecules appear, exactly identical to the original one. In each resulting “daughter” DNA molecule, one strand appears to be entirely derived from the original one, while the other is newly synthesized.
The main thing that needs to be emphasized once again is that the potential ability for accurate reproduction is inherent in the double-stranded complementary structure of DNA itself, and the discovery of this, of course, constitutes one of the main achievements of biology.
However, the problem of DNA reproduction (reduplication) is not limited to stating the potential ability of its structure to accurately reproduce its nucleotide sequence. The fact is that DNA itself is not a self-replicating molecule at all. To carry out the process of DNA synthesis and reproduction according to the scheme described above, the activity of a special enzymatic complex called DNA polymerase is necessary. Apparently, it is this enzyme that carries out the sequential process of separation of two chains from one end of the DNA molecule to the other with the simultaneous polymerization of free nucleotides on them according to the complementary principle. Thus, DNA, like a matrix, only sets the order of arrangement of nucleotides in the synthesized chains, and the process itself is carried out by the protein. The work of the enzyme during DNA reduplication is one of the most interesting problems today. Apparently, the DNA polymerase actively crawls along the double-stranded DNA molecule from one end to the other, leaving behind a forked, reduplicated “tail.” The physical principles of this protein’s operation are not yet clear.
However, DNA and its individual functional sections, which carry information about the structure of proteins, do not themselves directly participate in the process of creating protein molecules. The first step towards the realization of this information recorded in DNA chains is the so-called process of transcription, or “rewriting”. In this process, the synthesis of a chemically related polymer, ribonucleic acid (RNA), occurs on the DNA chain, as on a matrix. The RNA molecule is a single chain, the monomers of which are four types of ribonucleotides, which are considered as a slight modification of the four types of deoxyribonucleotides of DNA. The sequence of location of the four types of ribonucleotides in the resulting RNA chain exactly repeats the sequence of location of the corresponding deoxyribonucleotides of one of the two DNA chains. In this way, the nucleotide sequence of genes is copied in the form of RNA molecules, i.e. the information recorded in the structure of a given gene is completely transcribed into RNA. A large, theoretically unlimited number of such “copies” - RNA molecules - can be removed from each gene. These molecules, rewritten in many copies as “copies” of genes and therefore carrying the same information as genes, disperse throughout the cell. They are already in direct contact with the protein-synthesizing particles of the cell and take a “personal” part in the processes of creating protein molecules. In other words, they move information from the place where it is stored to the places where it is implemented. Accordingly, these RNAs are referred to as messenger or messenger RNAs, abbreviated as mRNA (or mRNA).
It was found that the messenger RNA chain is synthesized directly using the corresponding DNA section as a template. In this case, the synthesized mRNA chain exactly copies one of the two DNA chains in its nucleotide sequence (assuming that uracil (U) in RNA corresponds to its derivative thymine (T) in DNA). This occurs on the basis of the same structural principle of complementarity that determines DNA reduplication (Fig. 18). It turned out that when mRNA is synthesized on DNA in a cell, only one DNA strand is used as a template for the formation of an mRNA chain. Then each G of this DNA chain will correspond to a C in the RNA chain under construction, each C of the DNA chain will correspond to a G in the RNA chain, each T of the DNA chain will correspond to an A in the RNA chain, and each A of the DNA chain will correspond to a Y in the RNA chain. As a result, the resulting RNA strand will be strictly complementary to the template DNA strand and, therefore, identical in nucleotide sequence (taking T = Y) to the second DNA strand. In this way, information is “rewritten” from DNA to RNA, i.e. transcription. The “rewritten” combinations of nucleotides in the RNA chain already directly determine the arrangement of the corresponding amino acids they encode in the protein chain.
Here, as when considering DNA reduplication, it is necessary to point out its enzymatic nature as one of the most significant aspects of the transcription process. DNA, which is the matrix in this process, completely determines the location of nucleotides in the synthesized mRNA chain, all the specificity of the resulting RNA, but the process itself is carried out by a special protein - an enzyme. This enzyme is called RNA polymerase. Its molecule has a complex organization that allows it to actively move along the DNA molecule, while simultaneously synthesizing an RNA chain complementary to one of the DNA chains. The DNA molecule, which serves as a template, is not consumed or changed, remaining in its original form and being always ready for such rewriting from it of an unlimited number of “copies” - mRNA. The flow of these mRNAs from DNA to ribosomes constitutes the flow of information that ensures the programming of the protein synthesizing apparatus of the cell, the entire set of its ribosomes.
Thus, the considered part of the diagram describes the flow of information coming from DNA in the form of mRNA molecules to intracellular particles that synthesize proteins. Now we turn to a different kind of flow - to the flow of the material from which the protein must be created. The elementary units - monomers - of a protein molecule are amino acids, of which there are 20 different varieties. To create (synthesize) a protein molecule, free amino acids present in the cell must be involved in the appropriate flow entering the protein-synthesizing particle, and there they are arranged in a chain in a certain unique way, dictated by messenger RNA. This involvement of amino acids - the building blocks for protein creation - is carried out through the attachment of free amino acids to special RNA molecules of a relatively small size. These RNAs, which serve to attach free amino acids to them, will not be informational, but carry a different adapter function, the meaning of which will be seen further. Amino acids are attached to one end of small chains of transfer RNA (tRNA), one amino acid per RNA molecule.
For each type of amino acid in the cell, there are specific adapter RNA molecules that attach only this type of amino acid. In this form, visiting RNA, amino acids enter protein-synthesizing particles.
The central point of the process of protein biosynthesis is the fusion of these two intracellular flows - the flow of information and the flow of material - in the protein-synthesizing particles of the cell. These particles are called ribosomes. Ribosomes are ultramicroscopic biochemical “machines” of molecular size, where specific proteins are assembled from incoming amino acid residues, according to the plan contained in messenger RNA. Although this diagram (Fig. 19) shows only one particle, each cell contains thousands of ribsomes. The number of ribosomes determines the overall intensity of protein synthesis in the cell. The diameter of one ribosomal particle is about 20 nm. By its chemical nature, a ribosome is a ribonucleoprotein: it consists of a special ribosomal RNA (this is the third class of RNA known to us in addition to messenger and adapter RNAs) and molecules of structural ribosomal protein. Together, this combination of several dozen macromolecules forms an ideally organized and reliable “machine” that has the ability to read the information contained in the mRNA chain and implement it in the form of a finished protein molecule of a specific structure. Since the essence of the process is that the linear arrangement of 20 types of amino acids in a protein chain is uniquely determined by the location of four types of nucleotides in the chain of a chemically completely different polymer - nucleic acid (mRNA), this process occurring in the ribosome is usually referred to as “translation” or “translation” - translation, as it were, from a 4-letter alphabet of nucleic acid chains to a 20-letter alphabet of protein (polypeptide) chains. As can be seen, all three known classes of RNA are involved in the translation process: messenger RNA, which is the object of translation, ribosomal RNA, which plays the role of organizer of the protein-synthesizing ribonucleoprotein particle - ribosome, and adapter RNA, which performs the function of a translator.
The process of protein synthesis begins with the formation of amino acid compounds with adapter RNA molecules, or tRNA. In this case, the amino acid is first energetically “activated” due to its enzymatic reaction with the adenosine triphosphate (ATP) molecule, and then the “activated” amino acid is connected to the end of a relatively short tRNA chain, the increment in the chemical energy of the activated amino acid is stored in the form of the energy of the chemical bond between the amino acid and tRNA.
But at the same time, the second task is also being solved. The fact is that the reaction between an amino acid and a tRNA molecule is carried out by an enzyme designated as aminoacyl-tRNA synthetase. For each of the 20 types of amino acids, there are special enzymes that carry out a reaction involving only this amino acid. Thus, there are at least 20 enzymes (aminoacyl-tRNA synthetase), each of which is specific for one type of amino acid. Each of these enzymes can react not with any tRNA molecule, but only with those that carry a strictly defined combination of nucleotides in their chain. Thus, due to the existence of a set of such specific enzymes that distinguish, on the one hand, the nature of the amino acid and, on the other, the nucleotide sequence of the tRNA, each of the 20 types of amino acids turns out to be “assigned” only to a certain tRNA with a given characteristic nucleotide combination.
Schematically, some aspects of the protein biosynthesis process, as far as we represent them today, are given in Fig. 19.
Here, first of all, it is clear that the messenger RNA molecule is connected to the ribosome or, as they say, the ribosome is “programmed” by the messenger RNA. At any given moment, only a relatively short segment of the mRNA chain is located directly in the ribosome itself. But it is precisely this segment that, with the participation of the ribosome, can interact with adapter RNA molecules. And here again the main role is played by the principle of complementarity, already discussed twice above.
This is the explanation of the mechanism of why a strictly defined amino acid corresponds to a given triplet of the mRNA chain. It can be seen that the necessary intermediate link, or adapter, when each amino acid “recognizes” its triplet on mRNA is adapter RNA (tRNA).
Further on the diagram (see Fig. 19) it is clear that in the ribosome, in addition to the tRNA molecule just discussed with an attached amino acid, there is another tRNA molecule. But, unlike the tRNA molecule discussed above, this tRNA molecule is attached at its end to the end of a protein (polypeptide) chain that is in the process of synthesis. This situation reflects the dynamics of events occurring in the ribosome during the synthesis of a protein molecule. This dynamic can be imagined as follows. Let's start with a certain intermediate moment, reflected in the diagram and characterized by the presence of a protein chain that has already begun to be built, tRNA attached to it and which has just entered the ribosome and contacted the triplet of a new tRNA molecule with its corresponding amino acid. Apparently, the very act of attaching a tRNA molecule to an mRNA triplet located at a given location on the ribosome leads to such mutual orientation and close contact between the amino acid residue and the protein chain under construction that a covalent bond arises between them. The connection occurs in such a way that the end of the protein chain under construction, attached to tRNA in the diagram, is transferred from this tRNA to the amino acid residue of the incoming aminoacyl-tRNA. As a result, the “right” tRNA, having played the role of a “donor”, will be free, and the protein chain will be transferred to the “acceptor” - the “left” (arrived) aminoacyl-tRNA, as a result the protein chain will be extended by one amino acid and attached to the “left” » tRNA. Following this, the “left” tRNA, together with the triplet of mRNA nucleotides associated with it, is transferred “to the right”, then the previous “donor” tRNA molecule will be displaced from here and leave the ribosomes, in its place a new tRNA will appear with a protein chain under construction, lengthened by one amino acid residue, and the mRNA chain will be advanced one triplet to the right relative to the ribosome. As a result of the movement of the mRNA chain one triplet to the right, the next vacant triplet (UUU) will appear in the ribosome, and the corresponding tRNA with an amino acid (phenylalanyl-tRNA) will immediately join it according to the complementary principle. This will again cause the formation of a covalent (peptide) bond between the protein chain under construction and the phenylalanine residue and, following this, the movement of the mRNA chain one triplet to the right with all the ensuing consequences, etc. In this way, the messenger RNA chain is pulled sequentially, triplet by triplet, through the ribosome, as a result of which the mRNA chain is “read” by the ribosome as a whole, from beginning to end. At the same time and in conjunction with this, a sequential, amino acid by amino acid, growth of the protein chain occurs. Accordingly, tRNA molecules with amino acids enter the ribosome one after another, and tRNA molecules without amino acids exit. Finding themselves in solution outside the ribosome, free tRNA molecules again combine with amino acids and again carry them into the ribosome, thus cycling themselves without destruction or change.
Central Dogma of Molecular biology - a generalizing rule for the implementation of genetic information observed in nature: information is transmitted from nucleic acids to protein, but not in the opposite direction. The rule was formulated by Francis Crick in 1958 and brought into line with the data accumulated by that time in 1970. The transition of genetic information from DNA to RNA and from RNA to protein is universal for all cellular organisms without exception and underlies the biosynthesis of macromolecules. Genome replication corresponds to the information transition DNA → DNA. In nature, there are also transitions RNA → RNA and RNA → DNA (for example, in some viruses), as well as changes in the conformation of proteins transmitted from molecule to molecule. Transcription and broadcast. Conventionally, the entire process of transcription and translation can be displayed in a diagram: Transcription is the process of reproducing information stored in DNA in the form of a single-stranded molecule and RNA (messenger RNA, which transfers information about the structure of the protein from the cell nucleus to the cell cytoplasm to ribosomes). This process is manifested in the synthesis of molecules and RNA using a DNA matrix. The RNA molecule also consists of nucleotides, each of which includes a phosphoric acid residue, the sugar ribose, and one of four nitrogenous bases (A, G, C and U-uracil instead of T-tuline). The basis of RNA synthesis is the principle of complementarity, i.e. opposite A in one DNA chain are located U in and RNA, and against G in DNA - C in and RNA (see Fig. Transcription - on the previous page), thus, RNA is a complementary copy of DNA or a specific section of it, and contains information encoding an amino acid or protein. Each amino acid in DNA and RNA is encrypted by a sequence of 3 nucleotides, i.e. - a triplet, which is called a codon. If in transcription the recognition of two molecules by each other is manifested only in the principle of complementarity, then in translation, in addition to complementarity (temporary association of a codon and RNA and an RNA anticodon (transfer RNA, which brings the amino acids necessary for protein synthesis, to the place of synthesis - ribosome - see Fig. Transcription) molecular recognition manifests itself in the process of joining an amino acid to tRNA using the enzyme codase. The fact is that the tRNA molecule consists of a head, which includes an anti-eAOA triplet, consisting of a sequence of three nucleotides, and a tail having a certain shape. As many types of tRNA anticosons exist, there are as many tail shapes, and each anticoson has its own tail shape in tRNA. As many tail shapes as there are, there are as many types of forms of the enzyme codase, which attaches amino acids to the tail, and the shape of each codase matches only the shape a certain amino acid. Thus, tRNA carries with it information not only in the n sequence of nucleotides in the anticoson but also in the form of the tail of the molecule. And the main transfer of information here is to reproduce the sequence of amino acids in the protein, which is suggested to the enzyme encoding the protein and RNA

| Previous materials: |
The genome corresponds to the information transition DNA → DNA. In nature, there are also transitions RNA → RNA and RNA → DNA (for example, in some viruses), as well as changes in the conformation of proteins transmitted from molecule to molecule.
Information contained in biological sequences
Biopolymers are biological polymers synthesized by living things. DNA, RNA and proteins are linear polymers that are assembled by sequentially attaching individual elements - monomers - to each other. The sequence of monomers encodes information, the rules of transmission of which are described by the central dogma. Information is transferred with high precision, deterministically, and one biopolymer is used as a template for the assembly of another polymer with a sequence that is completely determined by the sequence of the first polymer.
Universal methods of transmitting biological information
In living organisms there are three types of heterogeneous, that is, consisting of different polymer monomers - DNA, RNA and protein. Information can be transferred between them in nine (3 × 3 = 9) ways. The Central Dogma divides these nine types of information transmission into three groups:
- general types - found in most living organisms;
- special types - found as an exception, in viruses, in mobile genome elements or in the conditions of a biological experiment;
- unknown types - not detected.
General methods of transmitting information
Translation: RNA → protein
RNA replication: RNA → RNA
RNA replication is the copying of an RNA strand onto a complementary RNA strand using the enzyme RNA-dependent RNA polymerase. Viruses containing single-stranded (for example, picornaviruses, which include foot-and-mouth disease virus) or double-stranded RNA replicate in this way.
Direct translation of a protein on a DNA template: DNA → protein
Direct translation has been demonstrated in cell extracts of Escherichia coli. The extracts contained ribosomes, but not mRNA, proteins were synthesized from DNA introduced into the system; the antibiotic neomycin enhanced this effect.
Epigenetic changes
Epigenetic changes are changes in the expression of genes that are not caused by changes in genetic information (mutations). Epigenetic changes occur as a result of modifications in the level of gene expression, that is, their transcription and/or translation. The most studied type of epigenetic regulation is DNA methylation using DNA methyltransferase proteins, which leads to temporary inactivation of the methylated gene, depending on the living conditions of the organism. However, since the primary structure of the DNA molecule does not change, this exception cannot be considered a true example of information transfer from protein to DNA.
Prions
Prions are proteins that exist in two forms. One of the forms (conformations) of the protein is functional, usually soluble in water. The second form forms water-insoluble aggregates, often in the form of molecular polymer tubes. A monomer - a protein molecule - in this conformation is able to attach to other similar protein molecules, transferring them to a second, prion-like, conformation. In fungi, such molecules can be inherited. But, as in the case of DNA methylation, the primary structure of the protein in this case remains the same, and information is not transferred to nucleic acids.
The history of the term “dogma”
Horace Judson (ur. Horace Judson) wrote in the book “The Eighth Day of Creation”:
“I believed that dogma is an idea that is not supported by facts. Do you understand? And Crick exclaimed with pleasure: “I simply did not know what ‘hypothesis’ meant in the sequence hypothesis, besides, I wanted to suggest that this new assumption was more central and stronger ... As it turned out, the use of the term ‘dogma’ caused more trouble, for what it was worth... Many years later, Jacques Monod told me that apparently I did not understand what was meant by the word “dogma”, which means a part of faith that is not subject to doubt. I was vaguely wary of this meaning of the word, but since I believed that all religious beliefs are without foundation, I used the word as I understood it, and not as most other people understood it, applying it to a grand hypothesis, which, despite the confidence it inspired, was based on a small amount of direct experimental data."
Original text (English) // The Eighth Day of Creation: Makers of the Revolution in Biology (25th anniversary edition). - 1996.
Protein synthesis
1. Transcription(rewriting information from DNA to mRNA). In a certain section of DNA, hydrogen bonds are broken, resulting in two single strands. On one of them, mRNA is built according to the principle of complementarity. Then it detaches and goes into the cytoplasm, and the DNA chains are again connected to each other.
2. Processing(only in eukaryotes) – maturation of mRNA: removal of non-protein coding regions from it, as well as the addition of control regions.
3. Export of mRNA from the nucleus to the cytoplasm(only in eukaryotes). Occurs through nuclear pores; in total, approximately 5% of the total amount of mRNA in the nucleus is exported.
4. Synthesis of aminoacyl-tRNA. There are 61 aminoacyl-tRNA synthetases in the cytoplasm. It complementarily recognizes the amino acid and the tRNA that must carry it, and connects them to each other, consuming 1 ATP.
5. Translation (protein synthesis). Inside the ribosome, tRNA anticodons are attached to the mRNA codons according to the principle of complementarity. The ribosome connects the amino acids brought by the tRNA together to form a protein.
6. Protein maturation. Cutting out unnecessary fragments from a protein, attaching non-protein components (for example, heme), joining several polypeptides into a quaternary structure.
http://biokhimija.ru/lekcii-po-biohimii/21-matrichnye-biosintezy/95-transljacija.html
There are three processes of molecular biology
The main figure in matrix biosynthesis is the nucleic acids RNA and DNA. They are polymer molecules that contain five types of nitrogenous bases, two types of pentoses and phosphoric acid residues. Nitrogen bases in nucleic acids can be purine ( adenine, guanine) and pyrimidine ( cytosine,uracil(only in RNA), thymine(only in DNA)). Depending on the structure of carbohydrates, they are divided into ribonucleic acids– contain ribose (RNA), and deoxyribonucleic acids– contain deoxyribose (DNA).
The term " matrix biosyntheses" refers to the cell's ability to synthesize polymer molecules such as nucleic acids And squirrels, based on template – matrices. This ensures accurate transfer of the most complex structure from existing molecules to newly synthesized ones.
Basic postulate of molecular biology
In the vast majority of cases, the transfer of hereditary information from the mother cell to the daughter cell is carried out using DNA ( replication). For the cell itself to use genetic information, it requires RNA formed on a DNA matrix ( transcription). Further, RNA is directly involved in all stages of the synthesis of protein molecules ( broadcast), providing the structure and activity of the cell.
Information contained in biological sequences
Biopolymers are (biological) polymers synthesized by living things. DNA, RNA and proteins are linear polymers, that is, each monomer they contain is connected to at least two other monomers. The sequence of monomers encodes information, the rules of transmission of which are described by the central dogma. Information is transferred with high precision, deterministically, and one biopolymer is used as a template for the assembly of another polymer with a sequence that is completely determined by the sequence of the first polymer.
Universal methods of transmitting biological information
In living organisms there are three types of heterogeneous, that is, consisting of different polymer monomers - DNA, RNA and protein. Information transfer between them can be carried out in 3 × 3 = 9 ways. The Central Dogma divides these 9 types of information transfer into three groups:
- General - found in most living organisms;
- Special - found as an exception, in viruses and mobile genome elements or in the conditions of a biological experiment;
- Unknown - not found.
DNA replication (DNA → DNA)
DNA is the main way of transmitting information between generations of living organisms, so accurate duplication (replication) of DNA is very important. Replication is carried out by a complex of proteins that unwind the chromatin, then the double helix. After this, DNA polymerase and its associated proteins build an identical copy on each of the two chains.
Transcription (DNA → RNA)
Transcription is a biological process as a result of which the information contained in a section of DNA is copied onto the synthesized mRNA molecule. Transcription is carried out by transcription factors and RNA polymerase. In a eukaryotic cell, the primary transcript (pre-mRNA) is frequently edited. This process is called splicing.
Schematic diagram of the implementation of genetic information in pro- and eukaryotes.PROKARYOTES. In prokaryotes, protein synthesis by the ribosome (translation) is not spatially separated from transcription and can occur even before the completion of mRNA synthesis by RNA polymerase. Prokaryotic mRNAs are often polycistronic, meaning they contain several independent genes.
EUKARYOTES. Eukaryotic mRNA is synthesized as a precursor, pre-mRNA, which then undergoes complex staged maturation - processing, including the attachment of a cap structure to the 5" end of the molecule, the attachment of several tens of adenine residues to its 3" end (polyadenylation), excision of insignificant regions - introns and connecting significant regions - exons - to each other (splicing). In this case, the joining of exons of the same pre-mRNA can occur in different ways, leading to the formation of different mature mRNAs, and ultimately different protein variants (alternative splicing). Only mRNA that has successfully undergone processing is exported from the nucleus to the cytoplasm and is involved in translation.
Translation (RNA → protein)
RNA replication (RNA → RNA)
RNA replication is the copying of an RNA strand onto a complementary RNA strand using the enzyme RNA-dependent RNA polymerase. Viruses containing single-stranded (for example, picornaviruses, which include foot-and-mouth disease virus) or double-stranded RNA replicate in a similar way.
Direct translation of a protein on a DNA template (DNA → protein)
Direct translation has been demonstrated in cell extracts of Escherichia coli that contained ribosomes but not mRNA. Such extracts synthesized proteins from DNA introduced into the system, and the antibiotic neomycin enhanced this effect.
Epigenetic changes
Epigenetic changes are changes in the expression of genes that are not caused by changes in genetic information (mutations). Epigenetic changes occur as a result of modifications in the level of gene expression, that is, their transcription and/or translation. The most studied type of epigenetic regulation is DNA methylation using DNA methyltransferase proteins, which leads to temporary inactivation of the methylated gene, depending on the living conditions of the organism. However, since the primary structure of the DNA molecule does not change, this exception cannot be considered a true example of information transfer from protein to DNA.
Prions
Prions are proteins that exist in two forms. One of the forms (conformations) of the protein is functional, usually soluble in water. The second form forms water-insoluble aggregates, often in the form of molecular polymer tubes. A monomer - a protein molecule - in this conformation is able to connect to other similar protein molecules, transferring them to a second, prion-like, conformation. In fungi, such molecules can be inherited. But, as in the case of DNA methylation, the primary structure of the protein in this case remains the same, and information is not transferred to nucleic acids.
The history of the term “dogma”
Original text(English)
My mind was, that a dogma was an idea for which there was no reasonable evidence. You see?!" And Crick gave a roar of delight. "I just didn"t know what dogma meant. And I could just as well have called it the "Central Hypothesis," or - you know. Which is what I meant to say Dogma was just a catch phrase
In addition, in his autobiographical book What Mad Pursuit, Crick wrote about the choice of the word “dogma” and the problems caused by this choice:
“I called this idea the central dogma, I suspect, for two reasons. I had already used the word hypothesis in the sequence hypothesis, and besides, I wanted to suggest that this new assumption was more central and stronger... As it turned out, the use of the term dogma caused more trouble than it was worth... Many years later, Jacques Monod told me that Apparently I did not understand what is meant by the word dogma, which means a part of faith that is not subject to doubt. I was vaguely wary of this meaning of the word, but since I believed that all religious beliefs are without foundation, I used the word as I understood it, and not as most other people understood it, applying it to a grand hypothesis, which, despite the confidence it inspired, was based on a small amount of direct experimental data."
Original text(English)
I called this idea the central dogma, for two reasons, I suspect. I had already used the obvious word hypothesis in the sequence hypothesis, and in addition I wanted to suggest that this new assumption was more central and more powerful. ... As it turned out, the use of the word dogma caused almost more trouble than it was worth.... Many years later Jacques Monod pointed out to me that I did not appear to understand the correct use of the word dogma, which is a belief that cannot be doubted. I did apprehend this in a vague sort of way but since I thought that all religious beliefs were without foundation, I used the word the way I myself thought about it, not as most of the world does, and simply applied it to a grand hypothesis that, however plausible, had little direct experimental support.
see also
Notes
Links
- B. J. McCarthy, J. J. Holland. Denatured DNA as a Direct Template for in vitro Protein Synthesis // PNAS. - 1965. - T. 54. - P. 880-886.
- Werner, E. Genome Semantics, In Silico Multicellular Systems and the Central Dogma // FEBS Letters. - 2005. - V. 579. - S. 1779-1782. PMID 15763551
- Horace Freeland Judson. Chapter 6: My mind was, that a dogma was an idea for which there was no reasonable evidence. Do you see?! // The Eighth Day of Creation: Makers of the Revolution in Biology (25th anniversary edition). - 1996.
Related posts:
 Charles's law: at a constant volume, the pressure of a gas changes in direct proportion to the absolute temperature. The relationship between the volume and pressure of a gas.
Charles's law: at a constant volume, the pressure of a gas changes in direct proportion to the absolute temperature. The relationship between the volume and pressure of a gas.
 Egyptian pharaohs were white-skinned
Egyptian pharaohs were white-skinned
 Talismans and symbols of ancient Egypt
Talismans and symbols of ancient Egypt
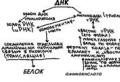 The Central Dogma of Molecular Genetics
The Central Dogma of Molecular Genetics
 Russian culture in the first half of the 19th century
Russian culture in the first half of the 19th century